Let’s Learn JavaScript Closures


Closures are a fundamental JavaScript concept that every serious programmer should know inside-out.
The Internet is packed with great explanations of “what” closures are, but few deep-dives into the “why” side of things.
I find that understanding the internals ultimately gives developers a stronger grasp of their tools, so this post will be dedicated to the nuts and bolts of how and why closures work the way they do.
Hopefully you’ll walk away better equipped to take advantage of closures in your day-to-day work. Let’s get started!
What is a closure?
Closures are an extremely powerful property of JavaScript (and most programming languages). As defined on MDN:
Closures are functions that refer to independent (free) variables. In other words, the function defined in the closure ‘remembers’ the environment in which it was created.
Note: Free variables are variables that are neither locally declared nor passed as parameter.
Let’s look at some examples:
Example 1:
In the example above, the function numberGenerator creates a local “free” variable num (a number) and checkNumber (a function which prints num to the console). The function checkNumber doesn’t have any local variables of its own — however, it does have access to the variables within the outer function, numberGenerator, because of a closure. Therefore, it can use the variable num declared in numberGenerator to successfully log it to the console even after numberGenerator has returned.
Example 2:
In this example we’ll demonstrate that a closure contains any and all local variables that were declared inside the outer enclosing function.
Notice how the variable hello is defined after the anonymous function — but can still access the hello variable. This is because the hello variable has already been defined in the function “scope” at the time of creation, making it available when the anonymous function is finally executed. (Don’t worry, I’ll explain what “scope” means later in the post. For now, just roll with it!)
Understanding the High Level
These examples illustrated “what” closures are on a high level. The general theme is this: we have access to variables defined in enclosing function(s) even after the enclosing function which defines these variables has returned. Clearly, something is happening in the background that allows those variables to still be accessible long after the enclosing function that defined them has returned.
To understand how this is possible, we’ll need to touch on a few related concepts — starting 3000 feet up and slowly climbing our way back down to the land of closures. Let’s start with the overarching context within which a function is run, known as “Execution context”.
Execution Context
Execution context is an abstract concept used by the ECMAScript specification to track the runtime evaluation of code. This can be the global context in which your code is first executed or when the flow of execution enters a function body.


At any point in time, there can only be one execution context running. That’s why JavaScript is “single threaded,” meaning only one command can be processed at a time. Typically, browsers maintain this execution context using a “stack.” A stack is a Last In First Out (LIFO) data structure, meaning the last thing that you pushed onto the stack is the first thing that gets popped off it. (This is because we can only insert or delete elements at the top of the stack.) The current or “running” execution context is always the top item in the stack. It gets popped off the top when the code in the running execution context has been completely evaluated, allowing the next top item to take over as running execution context.
Moreover, just because an execution context is running doesn’t mean that it has to finish running before a different execution context can run. There are times when the running execution context is suspended and a different execution context becomes the running execution context. The suspended execution context might then at a later point pick back up where it left off. Anytime one execution context is replaced by another like this, a new execution context is created and pushed onto the stack, becoming the current execution context.


For a practical example of this concept in action in the browser, see the example below:
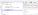

Then when boop returns, it gets popped off the stack and bar is resumed:


When we have a bunch of execution contexts running one after another — often being paused in the middle and then later resumed — we need some way to keep track of state so we can manage the order and execution of these contexts. And that is in fact the case; as per the ECMAScript spec, each execution context has various state components that are used to keep track of the progress the code in each context has made. These include:
- Code evaluation state: Any state needed to perform, suspend, and resume evaluation of the code associated with this execution context
- Function: The function object which the execution context is evaluating (or null if the context being evaluated is a script or module)
- Realm: A set of internal objects, an ECMAScript global environment, all of the ECMAScript code that is loaded within the scope of that global environment, and other associated state and resources
- Lexical Environment: Used to resolve identifier references made by code within this execution context.
- Variable Environment: Lexical Environment whose EnvironmentRecord holds bindings created by VariableStatements within this execution context.
If this sounds too confusing to you, don’t worry. Of all these variables, the Lexical Environment variable is the one that’s most interesting to us because it explicitly states that it resolves “identifier references” made by code within this execution context. You can think of “identifiers” as variables. Since our original goal was to figure out how it’s possible for us to magically access variables even after a function (or “context”) has returned, Lexical Environment looks like something we should dig into!
Note: Technically, both Variable Environment and Lexical Environment are used to implement closures. But for simplicity’s sake, we’ll generalize it to an “Environment”. For a detailed explanation on the difference between Lexical and Variable Environment, see Dr. Alex Rauschmayer’s excellent article.
Lexical Environment
By definition: A Lexical Environment is a specification type used to define the association of Identifiers to specific variables and functions based upon the lexical nesting structure of ECMAScript code. A Lexical Environment consists of an Environment Record and a possibly null reference to an outer Lexical Environment. Usually a Lexical Environment is associated with some specific syntactic structure of ECMAScript code such as a FunctionDeclaration, a BlockStatement, or a Catch clause of a TryStatement and a new Lexical Environment is created each time such code is evaluated. — ECMAScript-262/6.0
Let’s break this down.
- “Used to define the association of Identifiers”: The purpose of a Lexical Environment is to manage data (i.e. identifiers) within code. In other words, it gives meaning to identifiers. For instance, if we had a line of code “console.log(x / 10)”, it’s meaningless to have a variable (or “identifier”) x without something that provides meaning for that variable. The Lexical Environments provides this meaning (or “association”) via its Environment Record (see below).
- “Lexical Environment consists of an Environment Record”: An Environment Record is a fancy way to say that it keeps a record of all identifiers and their bindings that exist within a Lexical Environment. Every Lexical Environment has it’s own Environment Record.
- “Lexical nesting structure”: This is the interesting part, which is basically saying that an inner environment references the outer environment that surrounds it, and that this outer environment can have its own outer environment as well. As a result, an environment can serve as the outer environment for more than one inner environment. The global environment is the only Lexical environment that does not have an outer environment. The language here is tricky, so let’s use a metaphor and think of lexical environments like layers of an onion: the global environment is the outermost layer of the onion; every subsequent layer below is nested within.


Abstractly, the environment looks like this in pseudocode:
- “A new Lexical Environment is created each time such code is evaluated”: Each time an enclosing outer function is called, a new lexical environment is created. This is important — we’ll come back to this point again at the end. (Side note: a function is not the only way to create a Lexical Environment. Others include a block statement or a catch clause. For simplicity’s sake, I’ll focus on environment created by functions throughout this post)
In short, every execution context has a Lexical Environment. This Lexical environments holds variables and their associated values, and also has a reference to its outer environment. The Lexical Environment can be the global environment, a module environment (which contains the bindings for the top level declarations of a Module), or a function environment (environment created due to the invocation of a function).
Scope Chain
Based on the above definition, we know that an environment has access to its parent’s environment, and its parent environment has access to its parent environment, and so on. This set of identifiers that each environment has access to is called “scope.” We can nest scopes into a hierarchical chain of environments known as the “scope chain”.
Let’s look at an example of this nesting structure:
As you can see, bar is nested within foo. To help you visualize the nesting, see the diagram below:


We’ll revisit this example later in the post.
This scope chain, or chain of environments associated with a function, is saved to the function object at the time of its creation. In other words, it’s defined statically by location within the source code. (This is also known as “lexical scoping”.)
Let’s take a quick detour to understand the difference between “dynamic scope” and “static scope”, which will help clarify why static scope (or lexical scope) is necessary in order to have closures.
Detour: Dynamic Scope vs. Static Scope
Dynamic scoped languages have “stack-based implementations”, meaning that the local variables and arguments of functions are stored on a stack. Therefore, the runtime state of the program stack determines what variable you are referring to.
On the other hand, static scope is when the variables referenced in a context are recorded at the time of creation. In other words, the structure of the program source code determines what variables you are referring to.
At this point, you might be wondering how dynamic scope and static scope are different. Here’s two examples to help illustrate:
Example 1:
We see above that the static scope and dynamic scope return different values when the function bar is invoked.
With static scope, the return value of bar is based on the value of x at the time of foo’s creation. This is because of the static and lexical structure of the source code, which results in x being 10 and the result being 15.
Dynamic scope, on the other hand, gives us a stack of variable definitions tracked at runtime — such that which x we use depends on what exactly is in scope and has been defined dynamically at runtime. Running the function bar pushes x = 2 onto the top of the stack, making foo return 7.
Example 2:
Similarly, in the dynamic scope example above the variable myVar is resolved using the value of myVar at the place where the function is called. Static scope, on the other hand, resolves myVar to the variable that was saved in the scope of the two IIFE functions at creation.
As you can see, dynamic scope often leads to some ambiguity. It’s not exactly made clear which scope the free variable will be resolved from.
Closures
Some of that may strike you as off-topic, but we’ve actually covered everything we need to know to understand closures:
Every function has an execution context, which comprises of an environment that gives meaning to the variables within that function and a reference to its parent’s environment. A reference to the parent’s environment makes all variables in the parent scope available for all inner functions, regardless of whether the inner function(s) are invoked outside or inside the scope in which they were created.
So, it appears as if the function “remembers” this environment (or scope) because the function literally has a reference to the environment (and the variables defined in that environment)!
Coming back to the nested structure example:
Based on our understanding of how environments work, we can say that the environment definitions for the above example look something like this (note, this is purely pseudocode):
When we invoke the function test, we get 45, which is the return value from invoking the function bar (because foo returned bar). bar has access to the free variable y even after the function foo has returned because bar has a reference to y through its outer environment, which is foo’s environment! bar also has access to the global variable x because foo’s environment has access to the global environment. This is called “scope-chain lookup.”
Returning to our discussion of dynamic scope vs static scope: for closures to be implemented, we can’t use dynamic scoping via a dynamic stack to store our variables. The reason is because it would mean that when a function returns, the variables would be popped off the stack and no longer available — which contradicts our initial definition of a closure. What happens instead is that the closure data of the parent context is saved in what’s known as the “heap,” which allows for the data to persist after the function call that made them returns (i.e. even after the execution context is popped off the execution call stack).
Make sense? Good! Now that we understand the internals on an abstract level, let’s look at a couple more examples:
Example 1:
One canonical example/mistake is when there’s a for-loop and we try to associate the counter variable in the for-loop with some function in the for-loop:
Going back to what we just learned, it becomes super easy to spot the mistake here! Abstractly, here’s what the environment looks like this by the time the for-loop exits:
The incorrect assumption here was that the scope is different for all five functions within the result array. Instead, what’s actually happening is that the environment (or context/scope) is the same for all five functions within the result array. Therefore, every time the variable i is incremented, it updates scope — which is shared by all the functions. That’s why any of the 5 functions trying to access i returns 5 (i is equal to 5 when the for-loop exits).
One way to fix this is to create an additional enclosing context for each function so that they each get their own execution context/scope:
Yay! That fixed it :)
Another, rather clever approach is to use let instead of var, since let is block-scoped and so a new identifier binding is created for each iteration in the for-loop:
Tada! :)
Example 2:
In this example, we’ll show how each call to a function creates a new separate closure:
In this example, we can see that each call to the function iCantThinkOfAName creates a new closure, namely foo and bar. Subsequent invocations to either closure functions updates the closure variables within that closure itself, demonstrating that the variables in each closure continue to be usable by iCantThinkOfAName’s doSomething function long after iCantThinkOfAName returns.
Example 3:
What we can observe is that mysteriousCalculator is in the global scope, and it returns two functions. Abstractly, the environments for the example above look like this:
Because our add and subtract functions have a reference to the mysteriousCalculator function environment, they’re able to make use of the variables in that environment to calculate the result.
Example 4:
One final example to demonstrate an important use of closures: to maintain a private reference to a variable in the outer scope.
This is a very powerful technique — it gives the closure function guessPassword exclusive access to the password variable, while making it impossible to access the password from the outside.
Tl;dr
- Execution context is an abstract concept used by the ECMAScript specification to track the runtime evaluation of code. At any point in time, there can only be one execution context that is executing code.
- Every execution context has a Lexical Environment. This Lexical environments holds identifier bindings (i.e. variables and their associated values), and also has a reference to its outer environment.
- The set of identifiers that each environment has access to is called “scope.” We can nest these scopes into a hierarchical chain of environments, known as the “scope chain”.
- Every function has an execution context, which comprises of a Lexical Environment that gives meaning to the variables within that function and a reference to its parent’s environment. And so it appears as if the function “remembers” this environment (or scope) because the function literally has a reference to this environment. This is a closure.
- A closure is created every time an enclosing outer function is called. In other words, the inner function does not need to return for a closure to be created.
- The scope of a closure in JavaScript is lexical, meaning it’s defined statically by its location within the source code.
- Closures have many practical use cases. One important use case is to maintain a private reference to a variable in the outer scope.
Clos(ure)ing remarks
I hope this post was helpful and gave you a mental model for how closures are implemented in JavaScript. As you can see, understanding the nuts and bolts of how they work makes it much easier to spot closures — not to mention saving a lot of headache when it’s time to debug.
PS: I’m human and make mistakes — so if you find any mistakes I’d love for you to let me know!
Further Reading
For the sake of brevity I left out a few topics that might be interesting to some readers. Here are some links that I wanted to share:
- What’s the VariableEnvironment within an execution context? Dr. Axel Rauschmayer does a phenomenol job explaining it so I’ll leave you off with a link to his blog post: http://www.2ality.com/2011/04/ecmascript-5-spec-lexicalenvironment.html
- What are the different types of Environment Records? Read the spec here: http://www.ecma-international.org/ecma-262/6.0/#sec-environment-records
- Excellent article by MDN on closures: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Closures
- Others? Please suggest and I’ll add them!